Thiết kế của AWS Glue như thế nào?

Quote from bsdinsight on 8 December 2023, 11:03How is AWS Glue used to architect a cloud solution?
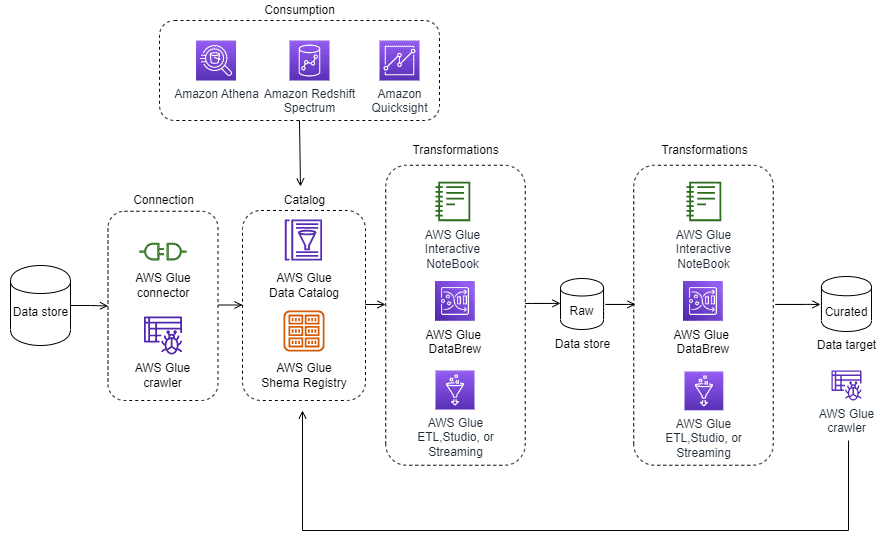
With AWS Glue, you can identify and build a technical data catalog for various data storage locations. You can use this data catalog as input and then carry out ETL or extract, load, transform (ELT) processes based on their requirements. The following architecture displays the typical pattern of connecting to data sources using connectors. Later, crawl the data to identify the schema, clean and standardize, and author the ETL process to generate raw data. Then, use the same ETL utilities provided by AWS Glue to create refined data. This data can finally be consumed through analytical query engines like Amazon Athena, Amazon Redshift, and Amazon QuickSight.
To learn more about how AWS Glue connects to data sources, choose each of the nine numbered markers.
What are the basic technical concepts of AWS Glue Studio?
To learn more about the basic technical concepts of AWS Glue Studio, expand each of the following ten categories.
ConnectionAn AWS Glue connection is an object in the Data Catalog that holds information such as login credentials, URI strings, VPC details, and more for a specific data store. AWS Glue components, such as crawlers, jobs, and development endpoints, use these connections to access particular data stores. Connections can be used for source and target data stores, and the same connection can be used multiple times by various crawlers or ETL jobs. For more information, see Adding an AWS Glue Connection(opens in a new tab).
CrawlerAn AWS Glue crawler can connect to various sources, identify their schema, and categorize them into data formats. They can also create metadata tables in the Data Catalog by using built-in data classifiers. For more information about crawlers, see Defining Crawlers in AWS Glue(opens in a new tab).
Datastore, data source, data targetA data store refers to physical storage where data is meant to persist permanently. An example of data stores in AWS would be Amazon S3 buckets and relational databases like Amazon Relational Database Service (Amazon RDS) for MySQL. These can serve as the input for processing or transformation. A data target refers to a data store where a process or transformation is output-written.
AWS Glue interactive sessionsWith AWS Glue interactive sessions, users can build and test data preparation needed for analytics applications. These sessions provide self-managed notebooks, which help developers write one-time queries or transformations that can be used to prepare data for ML. AWS Glue interactive sessions offer notebook editors, which can be deployed locally or remotely. Doing it this way can assist developers with quick development and testing time. AWS Glue integrates with AWS Glue Studio and Amazon SageMaker Studio for notebook management. For more information about AWS Glue interactive sessions, see Getting Started with AWS Glue interactive sessions(opens in a new tab).
DynamicFrameA DynamicFrame is a distributed table that facilitates the storage of nested data, such as structures and arrays. It does this by cleaning and reorganizing semi-structured datasets like JSON, Avro, and Apache logs. With DynamicFrame, there is no need for an upfront schema. The schema can be inferred without interruption so that transformations occur in a single pass. It is not difficult to handle unexpected changes because it tracks new fields and inconsistent changes in data types with choices, automatically marking and separating error records.
JobThe business logic necessary to carry out ETL work consists of a transformation script, data sources, and data targets. After the user has completed authoring the transformation, it can be initiated through job-based triggers, which can be scheduled or based on events.
File formatsAWS Glue supports two types of file formats:
- Apache Parquet format is a type of file format that structures data in a columnar format, rather than a row-based format like a CSV or Microsoft Excel file. Apache Parquet format is optimal for analytical engines like Athena or Amazon Redshift Spectrum to query over.
- AWS Glue now supports Apache Hudi, Apache Iceberg, and Delta Lake, which gives transactional capabilities to the data lake on Amazon S3.
TableThe metadata that represents user data is known as the table definition. Regardless of whether your data is stored in an Amazon S3 file, an Amazon RDS table, or elsewhere, a table defines the schema of that data. The table in the Data Catalog consists of information such as column names, data type definitions, partition details, and other metadata about the base dataset. The schema of your data is reflected in the AWS Glue table definition, while the actual data stays in its original data store (whether that be a file or a relational database table). The AWS Glue tables, which are cataloged in Data Catalog, can be used as sources or targets while creating an ETL job.
TransformTransform is the code logic that is used to manipulate data into a different format and translate that into business logic.
AWS Glue triggersA trigger, which initiates or starts an ETL job, can be defined based on a scheduled time or an event.
How is AWS Glue used to architect a cloud solution?
With AWS Glue, you can identify and build a technical data catalog for various data storage locations. You can use this data catalog as input and then carry out ETL or extract, load, transform (ELT) processes based on their requirements. The following architecture displays the typical pattern of connecting to data sources using connectors. Later, crawl the data to identify the schema, clean and standardize, and author the ETL process to generate raw data. Then, use the same ETL utilities provided by AWS Glue to create refined data. This data can finally be consumed through analytical query engines like Amazon Athena, Amazon Redshift, and Amazon QuickSight.
To learn more about how AWS Glue connects to data sources, choose each of the nine numbered markers.
What are the basic technical concepts of AWS Glue Studio?
To learn more about the basic technical concepts of AWS Glue Studio, expand each of the following ten categories.
An AWS Glue connection is an object in the Data Catalog that holds information such as login credentials, URI strings, VPC details, and more for a specific data store. AWS Glue components, such as crawlers, jobs, and development endpoints, use these connections to access particular data stores. Connections can be used for source and target data stores, and the same connection can be used multiple times by various crawlers or ETL jobs. For more information, see Adding an AWS Glue Connection(opens in a new tab).
An AWS Glue crawler can connect to various sources, identify their schema, and categorize them into data formats. They can also create metadata tables in the Data Catalog by using built-in data classifiers. For more information about crawlers, see Defining Crawlers in AWS Glue(opens in a new tab).
A data store refers to physical storage where data is meant to persist permanently. An example of data stores in AWS would be Amazon S3 buckets and relational databases like Amazon Relational Database Service (Amazon RDS) for MySQL. These can serve as the input for processing or transformation. A data target refers to a data store where a process or transformation is output-written.
With AWS Glue interactive sessions, users can build and test data preparation needed for analytics applications. These sessions provide self-managed notebooks, which help developers write one-time queries or transformations that can be used to prepare data for ML. AWS Glue interactive sessions offer notebook editors, which can be deployed locally or remotely. Doing it this way can assist developers with quick development and testing time. AWS Glue integrates with AWS Glue Studio and Amazon SageMaker Studio for notebook management. For more information about AWS Glue interactive sessions, see Getting Started with AWS Glue interactive sessions(opens in a new tab).
A DynamicFrame is a distributed table that facilitates the storage of nested data, such as structures and arrays. It does this by cleaning and reorganizing semi-structured datasets like JSON, Avro, and Apache logs. With DynamicFrame, there is no need for an upfront schema. The schema can be inferred without interruption so that transformations occur in a single pass. It is not difficult to handle unexpected changes because it tracks new fields and inconsistent changes in data types with choices, automatically marking and separating error records.
The business logic necessary to carry out ETL work consists of a transformation script, data sources, and data targets. After the user has completed authoring the transformation, it can be initiated through job-based triggers, which can be scheduled or based on events.
AWS Glue supports two types of file formats:
- Apache Parquet format is a type of file format that structures data in a columnar format, rather than a row-based format like a CSV or Microsoft Excel file. Apache Parquet format is optimal for analytical engines like Athena or Amazon Redshift Spectrum to query over.
- AWS Glue now supports Apache Hudi, Apache Iceberg, and Delta Lake, which gives transactional capabilities to the data lake on Amazon S3.
The metadata that represents user data is known as the table definition. Regardless of whether your data is stored in an Amazon S3 file, an Amazon RDS table, or elsewhere, a table defines the schema of that data. The table in the Data Catalog consists of information such as column names, data type definitions, partition details, and other metadata about the base dataset. The schema of your data is reflected in the AWS Glue table definition, while the actual data stays in its original data store (whether that be a file or a relational database table). The AWS Glue tables, which are cataloged in Data Catalog, can be used as sources or targets while creating an ETL job.
Transform is the code logic that is used to manipulate data into a different format and translate that into business logic.
A trigger, which initiates or starts an ETL job, can be defined based on a scheduled time or an event.

Quote from bsdinsight on 8 December 2023, 11:13Video giới thiệu và trình bày AWS Glue
[presto_player id=96703]
Video giới thiệu và trình bày AWS Glue
