Forum breadcrumbs – You are here:ForumGiải pháp BSD cung cấp: Microsoft FabricKiến trúc dữ liệu doanh nghiệp vớ …
Kiến trúc dữ liệu doanh nghiệp với Azure Data Factory và Databricks
bsdinsight@bsdinsight-com
837 Posts
#1 · 11 May 2025, 08:19
Quote from bsdinsight on 11 May 2025, 08:19Phân tích kiến trúc dữ liệu doanh nghiệp sử dụng Azure Data Factory và Databricks trong ngành bất động sảnBức hình trình bày một kiến trúc dữ liệu doanh nghiệp toàn diện, tận dụng Azure Data Factory kết hợp với Databricksđể quản lý, xử lý và chuẩn bị dữ liệu từ nhiều nguồn khác nhau, trước khi đưa vào trực quan hóa. Một câu hỏi quan trọng được đặt ra: tại sao trong Data Warehouse Layer lại sử dụng Databricks, trong khi Microsoft Fabric cũng cung cấp khả năng Data Warehouse? Dưới đây là phân tích chi tiết, kèm ví dụ áp dụng cho ngành bất động sản và giải thích lý do lựa chọn Databricks dựa trên yêu cầu của doanh nghiệp:Kiến trúc được xây dựng trên nền tảng Azure Data Lake Gen2, đóng vai trò là Enterprise Data Lakehouse – một kho lưu trữ dữ liệu tập trung, hỗ trợ cả dữ liệu có cấu trúc và không có cấu trúc. Dữ liệu được xử lý qua các tầng: Source Layer (Tầng nguồn), Data Warehouse Layer (Tầng kho dữ liệu), Presentation Layer (Tầng trình bày) và Visualization Layer (Tầng trực quan hóa). Mỗi tầng có vai trò cụ thể, đảm bảo dữ liệu được xử lý hiệu quả và phục vụ các nhu cầu phân tích khác nhau.
Ở Source Layer, dữ liệu được thu thập từ nhiều nguồn:
Tiếp theo là Data Warehouse Layer, nơi Azure Data Factory và Databricks phối hợp để xử lý và chuẩn hóa dữ liệu qua các giai đoạn:
Ở Presentation Layer, dữ liệu đã được xử lý bởi Azure Data Factory và Databricks sẽ được phục vụ thông qua Azure Synapse, với hai luồng chính:
Ngoài các tầng chính, kiến trúc còn tích hợp các công cụ quản lý và giám sát:
Phân tích kiến trúc dữ liệu doanh nghiệp sử dụng Azure Data Factory và Databricks trong ngành bất động sản
Bức hình trình bày một kiến trúc dữ liệu doanh nghiệp toàn diện, tận dụng Azure Data Factory kết hợp với Databricksđể quản lý, xử lý và chuẩn bị dữ liệu từ nhiều nguồn khác nhau, trước khi đưa vào trực quan hóa. Một câu hỏi quan trọng được đặt ra: tại sao trong Data Warehouse Layer lại sử dụng Databricks, trong khi Microsoft Fabric cũng cung cấp khả năng Data Warehouse? Dưới đây là phân tích chi tiết, kèm ví dụ áp dụng cho ngành bất động sản và giải thích lý do lựa chọn Databricks dựa trên yêu cầu của doanh nghiệp:
Kiến trúc được xây dựng trên nền tảng Azure Data Lake Gen2, đóng vai trò là Enterprise Data Lakehouse – một kho lưu trữ dữ liệu tập trung, hỗ trợ cả dữ liệu có cấu trúc và không có cấu trúc. Dữ liệu được xử lý qua các tầng: Source Layer (Tầng nguồn), Data Warehouse Layer (Tầng kho dữ liệu), Presentation Layer (Tầng trình bày) và Visualization Layer (Tầng trực quan hóa). Mỗi tầng có vai trò cụ thể, đảm bảo dữ liệu được xử lý hiệu quả và phục vụ các nhu cầu phân tích khác nhau.
Ở Source Layer, dữ liệu được thu thập từ nhiều nguồn:
-
Structured: Bao gồm các hệ thống như SAP/S4 HANA, nơi lưu trữ dữ liệu có cấu trúc (structured data).Ví dụ: Dữ liệu giao dịch bất động sản từ hệ thống SAP, như thông tin hợp đồng mua bán, giá trị giao dịch, thông tin khách hàng.
-
Streaming: Dữ liệu lớn từ các thiết bị IoT (Big Data Streams).Ví dụ: Dữ liệu cảm biến từ các tòa nhà thông minh (smart buildings), như mức tiêu thụ điện, nước, hoặc tình trạng bảo trì thang máy.
-
Unstructured: Dữ liệu không có cấu trúc như hình ảnh, âm thanh, video (Images, Audio, Video).Ví dụ: Hình ảnh chụp hiện trạng bất động sản, video quảng cáo dự án, hoặc bản ghi âm từ các buổi khảo sát ý kiến khách hàng.
-
Semi-structured: Các định dạng như CSV, logs, JSON, XML.Ví dụ: File CSV chứa danh sách các bất động sản đang rao bán từ đối tác môi giới, hoặc log truy cập từ website bất động sản.
Dữ liệu từ các nguồn này được thu thập thông qua quá trình Ingest (Thu thập), sử dụng Azure Data Factory để chuyển dữ liệu vào kho Azure Data Lake.
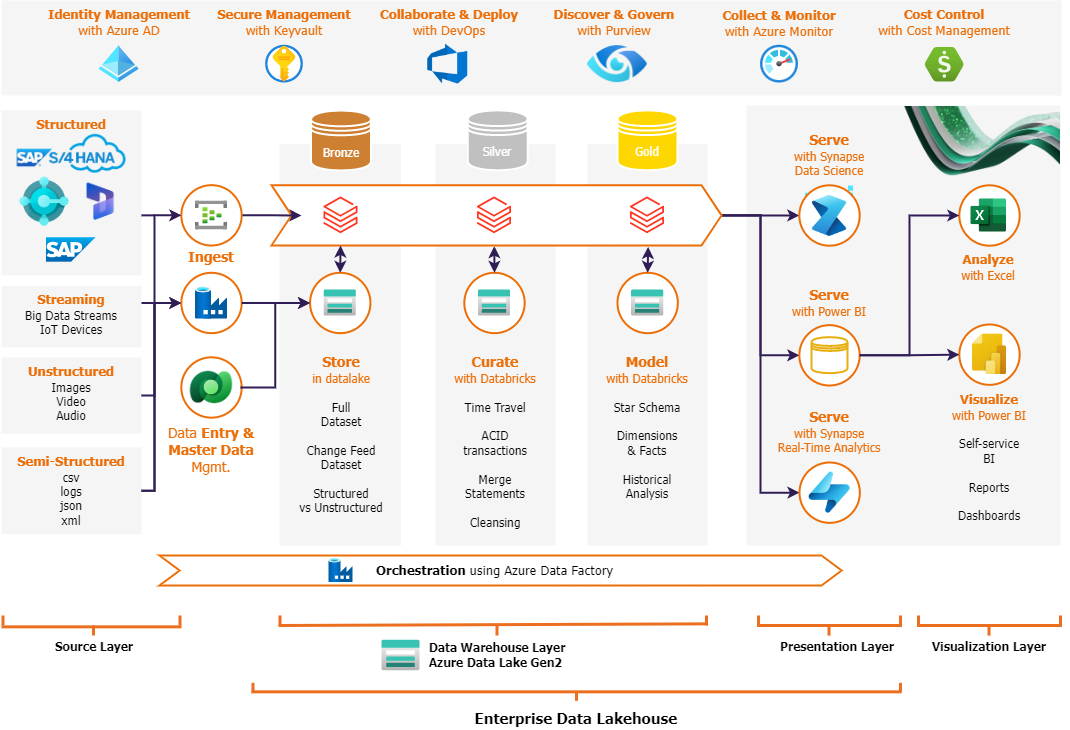
Tiếp theo là Data Warehouse Layer, nơi Azure Data Factory và Databricks phối hợp để xử lý và chuẩn hóa dữ liệu qua các giai đoạn:
-
Bronze: Lưu trữ dữ liệu thô (Raw Full Dataset), bao gồm cả dữ liệu có cấu trúc (structured), không có cấu trúc (unstructured), và bán cấu trúc (semi-structured), được giữ nguyên định dạng ban đầu mà chưa qua xử lý hay làm sạch.Ví dụ: Dữ liệu thô về giá đất tại từng khu vực (structured), hình ảnh bất động sản (unstructured), hoặc file CSV chứa thông tin dự án từ đối tác (semi-structured), hoặc lịch sử giao dịch chưa được xử lý.
-
Silver: Dữ liệu được làm sạch (Cleaning) và xử lý ACID transaction để đảm bảo tính toàn vẹn, với sự hỗ trợ của Databricks để thực hiện các tác vụ xử lý dữ liệu quy mô lớn.Ví dụ: Dữ liệu giá đất sau khi loại bỏ các giá trị trùng lặp hoặc lỗi, đảm bảo tính nhất quán giữa các nguồn.
-
Gold: Dữ liệu được mô hình hóa (Model with Databricks), áp dụng Star Schema và các bảng Dimensions & Facts để phục vụ phân tích. Databricks đóng vai trò quan trọng trong việc xử lý và chuyển đổi dữ liệu, đảm bảo dữ liệu sẵn sàng cho phân tích.Ví dụ: Bảng Dimensions chứa thông tin khu vực (vị trí, diện tích, tiện ích), bảng Facts chứa giá trị giao dịch bất động sản theo thời gian.
Quá trình Curate with Databricks được thực hiện trong tầng này, tận dụng khả năng xử lý dữ liệu phân tán của Databricks để chuẩn hóa và tối ưu dữ liệu. Azure Data Factory đóng vai trò điều phối (orchestration), quản lý luồng dữ liệu giữa các giai đoạn Bronze, Silver và Gold, đảm bảo dữ liệu được xử lý đúng quy trình. Tại đây, dữ liệu cũng được phân loại thành Structured vs Unstructured và hỗ trợ Change Feed Dataset (tập hợp dữ liệu thay đổi) để quản lý hiệu quả.
Ví dụ: Change Feed Dataset ghi nhận các thay đổi về giá bất động sản hoặc tình trạng pháp lý của dự án theo thời gian.
Lý do sử dụng Databricks trong Data Warehouse Layer thay vì Microsoft Fabric:
Mặc dù Microsoft Fabric cung cấp khả năng Data Warehouse và tích hợp chặt chẽ trong hệ sinh thái Microsoft, việc sử dụng Databricks trong kiến trúc này xuất phát từ một số yêu cầu cụ thể của doanh nghiệp:
-
Xử lý khối lượng dữ liệu lớn với hiệu suất cao: Doanh nghiệp trong ngành bất động sản thường phải xử lý khối lượng dữ liệu rất lớn, bao gồm cả dữ liệu có cấu trúc và không có cấu trúc. Databricks, với nền tảng Apache Spark, đáp ứng yêu cầu này nhờ khả năng xử lý dữ liệu phân tán nhanh chóng và hiệu quả.Ví dụ: Xử lý hàng triệu giao dịch bất động sản từ nhiều khu vực, kết hợp với dữ liệu không có cấu trúc như hình ảnh và video, cần sức mạnh tính toán phân tán của Databricks.
-
Yêu cầu xây dựng mô hình khoa học dữ liệu phức tạp: Doanh nghiệp có nhu cầu phát triển các mô hình dự đoán và phân tích sâu, đặc biệt trong ngành bất động sản, nơi dự đoán giá và xu hướng thị trường là yếu tố quan trọng. Databricks cung cấp môi trường linh hoạt, tích hợp tốt với các thư viện machine learning và hỗ trợ các ngôn ngữ như Python, Scala, R, đáp ứng nhu cầu này.Ví dụ: Xây dựng mô hình dự đoán giá bất động sản dựa trên dữ liệu lịch sử, vị trí và xu hướng thị trường, sử dụng các thư viện ML trong Databricks.
-
Tùy chỉnh pipeline xử lý dữ liệu: Ngành bất động sản thường yêu cầu các pipeline xử lý dữ liệu tùy chỉnh để đáp ứng các nhu cầu đặc thù, như phân tích dữ liệu từ nhiều nguồn không đồng nhất. Databricks, với sự hỗ trợ của cộng đồng lớn và khả năng tùy chỉnh cao, phù hợp với yêu cầu này.Ví dụ: Tùy chỉnh pipeline để xử lý dữ liệu giá đất từ các nguồn khác nhau (chính phủ, đối tác môi giới, dữ liệu nội bộ) và chuẩn hóa chúng thành một định dạng thống nhất.
-
Tích hợp với hệ sinh thái hiện có: Doanh nghiệp có thể đã sử dụng Databricks trong các dự án trước đó hoặc có đội ngũ kỹ thuật quen thuộc với công cụ này. Việc tiếp tục sử dụng Databricks giúp giảm thời gian đào tạo và tận dụng kinh nghiệm sẵn có, đồng thời vẫn tích hợp tốt với Azure Data Factory để điều phối luồng dữ liệu.
Lưu ý rằng Microsoft Fabric vẫn là một lựa chọn mạnh mẽ, đặc biệt trong các kịch bản cần một nền tảng hợp nhất, tích hợp chặt chẽ với Power BI và các công cụ Microsoft khác. Tuy nhiên, trong trường hợp này, Databricks được ưu tiên để đáp ứng các yêu cầu đặc thù của doanh nghiệp về hiệu suất, khoa học dữ liệu và khả năng tùy chỉnh.
Ở Presentation Layer, dữ liệu đã được xử lý bởi Azure Data Factory và Databricks sẽ được phục vụ thông qua Azure Synapse, với hai luồng chính:
-
Serve Real-time Analytics with Synapse: Phân tích thời gian thực, phù hợp với các ứng dụng cần phản hồi nhanh.Ví dụ: Phân tích thời gian thực về số lượng truy cập website bất động sản để điều chỉnh chiến dịch quảng cáo.
-
Serve Data Science with Synapse: Cung cấp dịch vụ về Khoa học dữ liệu (Data Science) với Synapse.Ví dụ: Xây dựng mô hình dự đoán giá bất động sản dựa trên dữ liệu lịch sử và các yếu tố như vị trí, tiện ích, xu hướng thị trường.
Cuối cùng, Visualization Layer sử dụng Power BI để trực quan hóa dữ liệu:
-
Analyze with Excel: Phân tích dữ liệu chi tiết bằng Excel.Ví dụ: Phân tích chi tiết doanh thu từ các dự án bất động sản tại từng khu vực bằng bảng tính Excel.
-
Visualize with Power BI: Tạo các báo cáo tự phục vụ (Self-service BI Reports) và bảng điều khiển (Dashboards).Ví dụ: Dashboard hiển thị xu hướng giá bất động sản, tỷ lệ bán hàng theo khu vực, hoặc hiệu quả chiến dịch marketing qua Power BI.
Ngoài các tầng chính, kiến trúc còn tích hợp các công cụ quản lý và giám sát:
-
Identity Management with Azure AD: Quản lý danh tính và quyền truy cập.Ví dụ: Phân quyền cho nhân viên kinh doanh chỉ truy cập dữ liệu khách hàng của khu vực họ phụ trách.
-
Secure Management with Keyvault: Bảo mật dữ liệu nhạy cảm.Ví dụ: Lưu trữ mã hóa thông tin hợp đồng và dữ liệu tài chính của khách hàng.
-
Collaborate & Deploy with DevOps: Hỗ trợ phát triển và triển khai liên tục.Ví dụ: Triển khai nhanh các bản cập nhật cho hệ thống phân tích giá bất động sản.
-
Discovery & Govern with Purview: Quản trị và khám phá dữ liệu.Ví dụ: Theo dõi nguồn gốc dữ liệu giá đất từ các đối tác để đảm bảo tuân thủ quy định pháp lý.
-
Collect & Monitor with Azure Monitor: Giám sát hiệu suất hệ thống.Ví dụ: Giám sát thời gian phản hồi của hệ thống khi khách hàng tra cứu thông tin bất động sản.
-
Cost Control with Cost Management: Quản lý chi phí sử dụng dịch vụ.Ví dụ: Tối ưu chi phí lưu trữ dữ liệu hình ảnh và video quảng cáo bất động sản.
Tóm lại, kiến trúc này tận dụng sự kết hợp giữa Azure Data Factory và Databricks để xây dựng một hệ sinh thái dữ liệu hiệu quả, từ thu thập, xử lý, phân tích đến trực quan hóa, rất phù hợp với ngành bất động sản. Azure Data Factory đảm nhiệm vai trò điều phối luồng dữ liệu, trong khi Databricks được sử dụng ở tầng Data Warehouse Layer để đáp ứng các yêu cầu cụ thể của doanh nghiệp về xử lý dữ liệu lớn, khoa học dữ liệu và tùy chỉnh pipeline. Microsoft Fabric vẫn là một giải pháp mạnh mẽ, nhưng trong trường hợp này, Databricks phù hợp hơn với các nhu cầu đặc thù. Kiến trúc này đáp ứng nhu cầu của cả phân tích thời gian thực (như theo dõi thị trường) và phân tích sâu (như dự đoán giá), đồng thời đảm bảo bảo mật, quản trị và tối ưu chi phí. Đây là một mô hình lý tưởng cho các doanh nghiệp bất động sản muốn khai thác dữ liệu hiệu quả trên quy mô lớn.
Click for thumbs down.0Click for thumbs up.0
