Search for answers or browse our knowledge base.
Data Warehousing and Analytics
Kho dữ liệu và phân tích dữ liệu (Data Warehousing and Analytics)
Azure Data Lake Storage | Azure Cosmos DB | Azure Data Factory | Azure SQL Database | Azure Table Storage
Kịch bản ví dụ này thể hiện một đường dẫn dữ liệu (data pipeline) tích hợp lượng lớn dữ liệu từ nhiều nguồn vào một nền tảng phân tích thống nhất trên Azure. Kịch bản cụ thể này dựa trên một giải pháp bán hàng và tiếp thị, nhưng các mô hình thiết kế (design patterns) có thể áp dụng cho nhiều ngành công nghiệp yêu cầu phân tích nâng cao trên các tập dữ liệu lớn, chẳng hạn như thương mại điện tử (e-commerce), bán lẻ (retail) và y tế (healthcare).
Kiến trúc (Architecture)
Hình ảnh: Đã tải xuống tệp Visio của kiến trúc này.
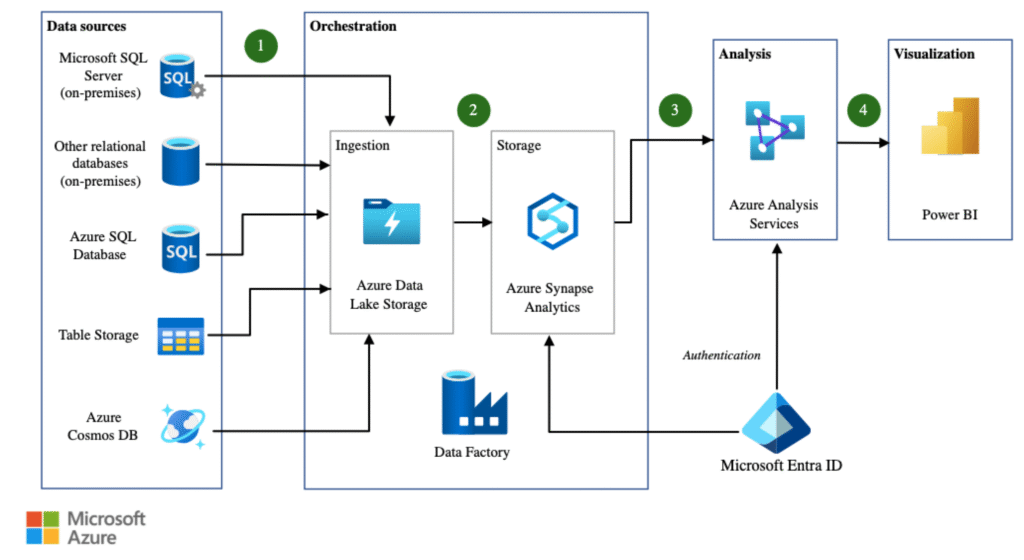
Luồng dữ liệu (Dataflow)
Dữ liệu di chuyển qua giải pháp theo các bước sau:
- Đối với mỗi nguồn dữ liệu, bất kỳ cập nhật nào được xuất định kỳ vào một khu vực tạm (staging area) trong Azure Data Lake Storage.
- Azure Data Factory tải dữ liệu tăng dần từ Azure Data Lake Storage vào các bảng tạm (staging tables) trong Azure Synapse Analytics. Dữ liệu được làm sạch (cleansed) và chuyển đổi (transformed) trong quá trình này. PolyBase có thể song song hóa quá trình cho các tập dữ liệu lớn.
- Sau khi tải một lô dữ liệu mới vào Data Warehouse, một mô hình bảng (tabular model) đã tạo trước đó trong Azure Analysis Services được làm mới. Mô hình ngữ nghĩa (semantic model) này đơn giản hóa việc phân tích dữ liệu kinh doanh và các mối quan hệ.
- Các nhà phân tích kinh doanh sử dụng Microsoft Power BI để phân tích dữ liệu trong kho thông qua mô hình ngữ nghĩa của Analysis Services.
Thành phần (Components)
Công ty có các nguồn dữ liệu trên nhiều nền tảng khác nhau:
- SQL Server tại chỗ (on-premises)
- Oracle tại chỗ
- Azure SQL Database
- Azure Table Storage
- Azure Cosmos DB
Dữ liệu được tải từ các nguồn dữ liệu khác nhau này bằng một số thành phần Azure:
Thành phần (tiếp tục)
- Data Factory điều phối việc chuyển đổi dữ liệu tạm thành một cấu trúc chung trong Azure Synapse. Data Factory sử dụng PolyBase khi tải dữ liệu vào Azure Synapse để tối đa hóa thông lượng (throughput).
- Azure Synapse là một hệ thống phân tán (distributed system) để lưu trữ và phân tích các tập dữ liệu lớn. Việc sử dụng xử lý song song quy mô lớn (massive parallel processing – MPP) khiến nó phù hợp để chạy các phân tích hiệu suất cao. Azure Synapse có thể sử dụng PolyBase để tải dữ liệu nhanh chóng từ Azure Data Lake Storage.
- Analysis Services cung cấp một mô hình ngữ nghĩa (semantic model) cho dữ liệu. Nó cũng có thể tăng hiệu suất hệ thống khi phân tích dữ liệu.
- Power BI là bộ công cụ phân tích kinh doanh (business analytics tools) để phân tích dữ liệu và chia sẻ thông tin chi tiết (insights). Power BI có thể truy vấn mô hình ngữ nghĩa được lưu trữ trong Analysis Services, hoặc truy vấn trực tiếp Azure Synapse.
- Microsoft Entra ID xác thực (authenticates) người dùng kết nối với máy chủ Analysis Services thông qua Power BI. Data Factory cũng có thể sử dụng Microsoft Entra ID để xác thực với Azure Synapse thông qua một chủ thể dịch vụ (service principal) hoặc danh tính được quản lý (Managed Identity) cho các tài nguyên Azure.
Các lựa chọn thay thế (Alternatives)
- Đường dẫn ví dụ bao gồm nhiều loại nguồn dữ liệu khác nhau. Kiến trúc này có thể xử lý nhiều loại nguồn dữ liệu quan hệ (relational) và phi quan hệ (non-relational).
- Data Factory điều phối các luồng công việc (workflows) cho đường dẫn dữ liệu. Nếu bạn chỉ muốn tải dữ liệu một lần hoặc theo nhu cầu (on-demand), bạn có thể sử dụng các công cụ như SQL Server bulk copy (bcp) và AzCopy để sao chép dữ liệu vào Azure Data Lake Storage. Sau đó, bạn có thể tải dữ liệu trực tiếp vào Azure Synapse bằng PolyBase.
- Nếu bạn có các tập dữ liệu rất lớn, hãy cân nhắc sử dụng Data Lake Storage, nơi cung cấp dung lượng lưu trữ không giới hạn cho dữ liệu phân tích.
- Azure Synapse không phù hợp với các khối lượng công việc giao dịch trực tuyến (OLTP workloads) hoặc các tập dữ liệu nhỏ hơn 250 GB. Trong những trường hợp này, bạn nên sử dụng Azure SQL Database hoặc SQL Server.
- Để so sánh các lựa chọn thay thế khác, xem:
- Chọn công nghệ điều phối đường dẫn dữ liệu trong Azure
- Chọn công nghệ xử lý hàng loạt trong Azure
- Chọn kho dữ liệu phân tích trong Azure
- Chọn công nghệ phân tích dữ liệu trong Azure
Chi tiết kịch bản (Scenario Details)
Ví dụ này thể hiện một công ty bán hàng và tiếp thị tạo ra các chương trình khuyến khích (incentive programs). Các chương trình này thưởng cho khách hàng, nhà cung cấp, nhân viên bán hàng và nhân viên. Dữ liệu là nền tảng cho các chương trình này, và công ty muốn cải thiện thông tin chi tiết (insights) thu được thông qua phân tích dữ liệu bằng Azure.
Công ty cần một cách tiếp cận hiện đại để phân tích dữ liệu, đảm bảo các quyết định được đưa ra dựa trên dữ liệu đúng vào thời điểm phù hợp. Các mục tiêu của công ty bao gồm:
- Kết hợp các loại nguồn dữ liệu khác nhau vào một nền tảng quy mô đám mây (cloud-scale platform).
- Chuyển đổi dữ liệu nguồn thành một cấu trúc và phân loại chung (common taxonomy and structure), để dữ liệu nhất quán và dễ so sánh.
- Tải dữ liệu bằng cách tiếp cận song song hóa cao (highly parallelized approach) có thể hỗ trợ hàng nghìn chương trình khuyến khích, mà không cần chi phí cao để triển khai và duy trì cơ sở hạ tầng tại chỗ.
- Giảm đáng kể thời gian cần thiết để thu thập và chuyển đổi dữ liệu, để tập trung vào việc phân tích dữ liệu.
Các trường hợp sử dụng tiềm năng (Potential Use Cases)
Cách tiếp cận này cũng có thể được sử dụng để:
- Thiết lập một Data Warehouse làm nguồn sự thật duy nhất (single source of truth) cho dữ liệu.
- Tích hợp các nguồn dữ liệu quan hệ với các tập dữ liệu không cấu trúc khác (unstructured datasets).
- Sử dụng mô hình ngữ nghĩa (semantic modeling) và các công cụ trực quan hóa mạnh mẽ (visualization tools) để phân tích dữ liệu đơn giản hơn.
Các cân nhắc (Considerations)
Những cân nhắc này triển khai các trụ cột của Khung Kiến trúc Tốt của Azure (Azure Well-Architected Framework), là một tập hợp các nguyên tắc định hướng để cải thiện chất lượng của một khối lượng công việc (workload). Để biết thêm thông tin, xem Khung Kiến trúc Tốt.
Các công nghệ trong kiến trúc này được chọn vì đáp ứng yêu cầu của công ty về khả năng mở rộng (scalability) và tính sẵn sàng (availability), đồng thời giúp kiểm soát chi phí.
Các cân nhắc (tiếp tục)
- Kiến trúc xử lý song song quy mô lớn (massive parallel processing architecture) của Azure Synapse cung cấp khả năng mở rộng và hiệu suất cao.
- Azure Synapse có các thỏa thuận mức dịch vụ được đảm bảo (service-level agreements – SLAs) và các phương pháp được khuyến nghị để đạt được tính sẵn sàng cao.
- Khi hoạt động phân tích thấp, công ty có thể mở rộng Azure Synapse theo nhu cầu, giảm hoặc thậm chí tạm dừng tính toán (compute) để giảm chi phí.
- Azure Analysis Services có thể được mở rộng (scaled out) để giảm thời gian phản hồi trong các khối lượng công việc truy vấn cao (high query workloads). Bạn cũng có thể tách biệt xử lý (processing) khỏi nhóm truy vấn (query pool), để các truy vấn của khách hàng không bị chậm lại bởi các hoạt động xử lý.
- Azure Analysis Services cũng có các thỏa thuận mức dịch vụ được đảm bảo và các phương pháp được khuyến nghị để đạt được tính sẵn sàng cao.
- Mô hình bảo mật của Azure Synapse cung cấp bảo mật kết nối (connection security), xác thực và ủy quyền (authentication and authorization) thông qua Microsoft Entra ID hoặc xác thực SQL Server, và mã hóa (encryption). Azure Analysis Services sử dụng Microsoft Entra ID cho quản lý danh tính (identity management) và xác thực người dùng.
Tối ưu hóa chi phí (Cost Optimization)
Tối ưu hóa chi phí tập trung vào các cách để giảm chi phí không cần thiết và cải thiện hiệu quả hoạt động. Để biết thêm thông tin, xem Danh sách kiểm tra đánh giá thiết kế để tối ưu hóa chi phí.
Xem mẫu giá cho kịch bản kho dữ liệu qua máy tính giá Azure (Azure pricing calculator). Điều chỉnh các giá trị để xem yêu cầu của bạn ảnh hưởng đến chi phí như thế nào.
- Azure Synapse cho phép bạn mở rộng mức tính toán (compute) và lưu trữ (storage) độc lập. Tài nguyên tính toán được tính phí theo giờ, và bạn có thể mở rộng hoặc tạm dừng các tài nguyên này theo nhu cầu. Tài nguyên lưu trữ được tính phí theo terabyte, vì vậy chi phí sẽ tăng khi bạn nhập thêm dữ liệu.
- Chi phí Data Factory dựa trên số lượng thao tác đọc/ghi (read/write operations), thao tác giám sát (monitoring operations) và các hoạt động điều phối (orchestration activities) được thực hiện trong một khối lượng công việc. Chi phí Data Factory sẽ tăng với mỗi luồng dữ liệu bổ sung và lượng dữ liệu được xử lý bởi mỗi luồng.
- Analysis Services có sẵn trong các bậc Developer, Basic và Standard. Các phiên bản được định giá dựa trên đơn vị xử lý truy vấn (query processing units – QPUs) và bộ nhớ khả dụng. Để giữ chi phí thấp hơn, hãy giảm thiểu số lượng truy vấn bạn chạy, lượng dữ liệu chúng xử lý và tần suất chúng chạy.
- Power BI có các tùy chọn sản phẩm khác nhau cho các yêu cầu khác nhau. Power BI Embedded cung cấp một tùy chọn dựa trên Azure để nhúng chức năng Power BI vào ứng dụng của bạn. Một phiên bản Power BI Embedded được bao gồm trong mẫu giá ở trên.
Người đóng góp (Contributors)
Bài viết này được duy trì bởi Microsoft. Nó được viết lần đầu bởi người đóng góp sau đây.
Tác giả chính:
- Alex Buck | Nhà phát triển nội dung cấp cao (Senior Content Developer)
Để xem các hồ sơ LinkedIn không công khai, đăng nhập vào LinkedIn.
Các bước tiếp theo (Next Steps)
- Xem kiến trúc tham chiếu Azure cho BI doanh nghiệp tự động (automated enterprise BI), bao gồm hướng dẫn triển khai một phiên bản của kiến trúc này trong Azure.
- Tìm hiểu thêm về các dịch vụ được sử dụng trong kịch bản này:
- Giới thiệu về Azure Data Lake Storage Gen2
- Tài liệu Azure Data Factory
- Hồ SQL chuyên dụng trong Azure Synapse Analytics là gì?
- Tài liệu Azure Analysis Services
- Tài liệu Power BI
- Tài liệu Microsoft Entra
