Hackolade và OpenMetadata: Kiến Trúc Tích Hợp Toàn Diện Từ Data Modeling Đến Data Governance
Tóm tắt nhanh: Một trong những thách thức lớn nhất trong data engineering hiện đại là khoảng cách giữa thiết kế dữ liệu (ai thiết kế schema và model) và quản trị dữ liệu (ai biết dữ liệu đang ở đâu, có ý nghĩa gì và chất lượng ra sao). Kiến trúc tích hợp Hackolade + OpenMetadata giải quyết chính xác khoảng cách này – tạo ra một vòng khép kín từ Data Modeling & Design, qua Storage & Processing, đến Data Governance & Catalog. Bài viết này phân tích từng tầng trong kiến trúc, vai trò của từng công cụ và lý do tích hợp này quan trọng với modern data teams.
Vấn Đề Mà Kiến Trúc Này Giải Quyết
Trong nhiều tổ chức, data stack đang bị chia cắt theo kiểu này:
- Data Architects thiết kế schema trong một công cụ riêng, rồi gửi email hoặc PDF cho data engineers
- Data Engineers implement schema theo cách họ hiểu, đôi khi khác với ý định ban đầu
- Data Warehouse chứa hàng trăm bảng nhưng không ai biết chính xác bảng nào đang được dùng, ai tạo ra và dữ liệu đến từ đâu
- Analysts và BI teams mất hàng giờ tìm đúng bảng, đúng field và hiểu ý nghĩa của từng column
- Data Governance teams không có visibility vào schema thực tế đang chạy trong production
Kết quả: metadata bị phân tán, lineage không rõ ràng, data quality khó kiểm soát và governance chỉ tồn tại trên giấy tờ.
Kiến trúc Hackolade + OpenMetadata được thiết kế để giải quyết toàn bộ chuỗi vấn đề này trong một hệ thống liên kết.
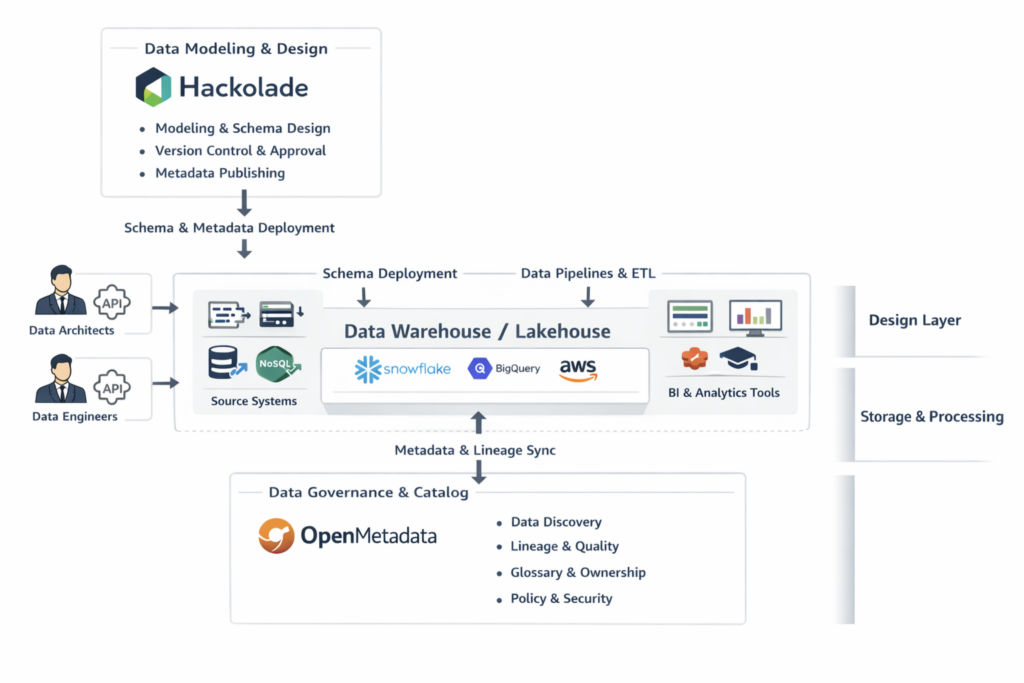
Tổng Quan Kiến Trúc: 3 Tầng, 1 Vòng Khép Kín
Kiến trúc được tổ chức theo 3 tầng (layers) với luồng dữ liệu và metadata chạy theo hai chiều:
┌─────────────────────────────────────────┐
│ DESIGN LAYER │
│ Hackolade – Data Modeling & Design │
│ (Data Architects + Data Engineers) │
└──────────────┬──────────────────────────┘
│ Schema & Metadata Deployment
▼
┌─────────────────────────────────────────┐
│ STORAGE & PROCESSING LAYER │
│ Data Warehouse / Lakehouse │
│ (Snowflake, BigQuery, AWS) │
│ + Source Systems + BI & Analytics │
└──────────────┬──────────────────────────┘
│ Metadata & Lineage Sync
▼
┌─────────────────────────────────────────┐
│ GOVERNANCE LAYER │
│ OpenMetadata – Data Governance & │
│ Catalog │
└─────────────────────────────────────────┘
Đây không phải luồng một chiều – Metadata & Lineage Sync đi ngược từ Data Warehouse lên OpenMetadata, tạo ra vòng phản hồi giúp governance luôn được cập nhật theo thực tế production.
TẦNG 1: DESIGN LAYER – Hackolade Làm Trung Tâm
Hackolade Là Gì?
Hackolade là công cụ Data Modeling & Schema Design chuyên biệt, hỗ trợ cả relational databases, NoSQL (MongoDB, Cassandra, DynamoDB) và cloud data warehouses (Snowflake, BigQuery, Redshift). Điểm mạnh của Hackolade so với các công cụ modeling truyền thống là khả năng làm việc với polyglot persistence – một data model duy nhất có thể generate schema cho nhiều loại database khác nhau.
Ba Chức Năng Cốt Lõi Trong Tầng Design
1. Modeling & Schema Design (Thiết kế model và schema)
Đây là điểm khởi đầu của toàn bộ kiến trúc. Data Architects sử dụng Hackolade để:
- Thiết kế Entity-Relationship Diagrams (ERD) và data models trực quan
- Định nghĩa tables, columns, data types, constraints và relationships
- Thiết kế schema cho cả SQL (Snowflake, BigQuery, Redshift) và NoSQL (MongoDB, Cassandra)
- Tạo JSON Schema, Avro Schema hoặc Protobuf cho data streaming
- Forward engineer: từ model generate ra DDL scripts để deploy
Điểm quan trọng: Hackolade không chỉ là công cụ vẽ diagram – nó là single source of truth cho schema definitions, nơi mọi thay đổi cấu trúc dữ liệu được thiết kế và phê duyệt trước khi deploy.
2. Version Control & Approval (Kiểm soát phiên bản và phê duyệt)
Hackolade tích hợp với Git (GitHub, GitLab, Bitbucket), cho phép:
- Schema-as-Code: Schema definitions được lưu dưới dạng JSON files trong Git repository, cùng với application code
- Pull Request workflow: Mọi thay đổi schema phải qua PR review và approval trước khi merge
- Change history: Biết ai thay đổi gì, khi nào và lý do – đây là audit trail quan trọng cho compliance
- Branch và merge: Có thể có nhiều phiên bản schema song song cho các feature branches khác nhau
- Diff và comparison: So sánh trực quan giữa các phiên bản schema để review changes
Đây là điểm mà Hackolade giải quyết một vấn đề rất thực tế: “Schema thay đổi nhưng không ai ghi lại lý do và ai approve.”
3. Metadata Publishing (Xuất bản metadata)
Sau khi schema được approve, Hackolade không chỉ generate DDL – nó còn publish metadata (descriptions, business definitions, tags, ownership information) ra các hệ thống downstream. Đây là cầu nối quan trọng với OpenMetadata ở tầng dưới.
Hai Vai Trò Sử Dụng Design Layer
Data Architects kết nối qua API để:
- Thiết kế và maintain conceptual/logical/physical data models
- Define business rules và data standards
- Phê duyệt schema changes từ data engineers
Data Engineers kết nối qua API để:
- Implement physical schemas theo design của architects
- Generate DDL scripts cho deployment
- Manage schema migrations và version control
TẦNG 2: STORAGE & PROCESSING LAYER – Trái Tim Của Data Stack
Thành Phần Của Tầng Storage & Processing
Tầng này bao gồm ba nhóm thành phần chính:
Source Systems (Hệ thống nguồn)
Dữ liệu gốc đến từ nhiều nguồn: relational databases (PostgreSQL, MySQL, SQL Server), NoSQL databases (MongoDB, Cassandra, DynamoDB), SaaS applications (Salesforce, SAP, HubSpot), streaming sources (Kafka, Kinesis) và flat files. Đây là nơi dữ liệu thô được tạo ra.
Data Warehouse / Lakehouse (Kho dữ liệu trung tâm)
Đây là trung tâm của tầng Storage & Processing, nơi dữ liệu từ source systems được ingestion, transform và lưu trữ để phân tích. Ba platform được hiển thị trong sơ đồ:
Snowflake: Cloud data warehouse nổi tiếng với kiến trúc tách biệt storage và compute, hỗ trợ semi-structured data (JSON, Parquet) và có Time Travel (quay về dữ liệu quá khứ). Đặc biệt phù hợp với workloads analytics và data sharing giữa các tổ chức.
Google BigQuery: Serverless data warehouse của Google Cloud, không cần quản lý infrastructure, tính phí theo lượng data được scan. Mạnh về xử lý petabyte-scale queries và tích hợp sâu với Google Cloud ecosystem và Looker.
AWS (Redshift/S3/Glue): Hệ sinh thái data của Amazon Web Services bao gồm Redshift (managed data warehouse), S3 (object storage cho data lake), Glue (managed ETL) và Lake Formation (data lake governance). Phù hợp với tổ chức đã đầu tư sâu vào AWS.
Thuật ngữ “Data Lakehouse” trong sơ đồ phản ánh xu hướng hiện đại: kết hợp tính linh hoạt của data lake (lưu trữ mọi loại dữ liệu, structured và unstructured) với khả năng query mạnh của data warehouse. Platforms như Databricks Delta Lake, Apache Iceberg và Apache Hudi là những ví dụ điển hình.
BI & Analytics Tools (Công cụ phân tích và trực quan hóa)
Sau khi dữ liệu được xử lý trong data warehouse/lakehouse, nó được tiêu thụ bởi các BI tools: Tableau, Power BI, Looker, Metabase, Superset… Đây là nơi business users tạo ra dashboards, reports và ad-hoc queries.
Hai Luồng Kết Nối Với Tầng Storage & Processing
Schema Deployment (từ Design Layer xuống): Khi schema được approve trong Hackolade, DDL scripts được deploy vào Data Warehouse/Lakehouse. Quá trình này có thể được tự động hóa qua CI/CD pipeline – mỗi khi schema PR được merge vào main branch, deployment tự động chạy.
Data Pipelines & ETL (từ Source Systems vào Data Warehouse): Data Engineers xây dựng và maintain các pipelines để move dữ liệu từ source systems vào data warehouse. Công cụ phổ biến: dbt (transform), Airbyte/Fivetran (ingestion), Apache Spark/Flink (streaming processing), Airflow/Prefect (orchestration).
TẦNG 3: GOVERNANCE LAYER – OpenMetadata Làm Trung Tâm
OpenMetadata Là Gì?
OpenMetadata là open-source data catalog và metadata management platform. Được thiết kế để trở thành central hub cho tất cả metadata của data organization – từ technical metadata (schema, lineage, quality) đến business metadata (definitions, ownership, policies).
So với các commercial alternatives như Collibra, Alation hay Atlan, OpenMetadata có ưu điểm là hoàn toàn open-source (Apache 2.0 license), có thể self-host và có cộng đồng đang phát triển mạnh.
Bốn Chức Năng Cốt Lõi Của OpenMetadata
1. Data Discovery (Khám phá dữ liệu)
Data Discovery giải quyết câu hỏi cơ bản nhất mà mọi data consumer đều gặp: “Tôi cần dữ liệu về X – tôi tìm ở đâu?”
OpenMetadata cung cấp:
- Unified search – tìm kiếm toàn bộ data assets (tables, dashboards, pipelines, ML models) trong một giao diện
- Asset catalog – browsable catalog với filtering theo owner, tag, tier, domain
- Rich metadata – mỗi asset có descriptions, sample data, column-level info, usage statistics và related assets
- Popularity signals – biết table nào được query nhiều nhất, dashboard nào được xem thường xuyên
- Following và notifications – data consumers có thể “follow” assets và nhận thông báo khi có thay đổi
Data Discovery tốt không chỉ tiết kiệm thời gian – nó giảm Shadow Analytics (người dùng tự tạo lại dữ liệu vì không tìm thấy source of truth).
2. Lineage & Quality (Dòng dõi dữ liệu và chất lượng)
Data Lineage trả lời câu hỏi: “Dữ liệu trong table này đến từ đâu và đi đến đâu?”
OpenMetadata track lineage ở nhiều cấp độ:
- Table-level lineage: Table A → Transform → Table B → Dashboard C
- Column-level lineage: Biết chính xác column “revenue” trong dashboard đến từ column nào trong source system, qua những bước transform nào
- Pipeline lineage: Aiflow DAGs, dbt models, Spark jobs được automatically tracked
- End-to-end traceability: Từ raw data trong source system đến số liệu hiển thị trên dashboard
Column-level lineage là đặc biệt có giá trị khi xảy ra data quality issue: thay vì mất hàng giờ tìm nguyên nhân, bạn có thể trace ngược từ dashboard → tables → pipelines → source system trong vài phút.
Data Quality trong OpenMetadata cho phép:
- Define và run data quality tests (freshness, completeness, uniqueness, referential integrity)
- Track quality scores theo thời gian
- Alert khi quality metrics drop dưới ngưỡng
- Integrate với dbt tests và Great Expectations
3. Glossary & Ownership (Từ điển và quyền sở hữu)
Business Glossary là tính năng quan trọng nhất cho data governance thực sự:
- Định nghĩa tập trung các business terms: “Revenue” nghĩa là gì? “Active Customer” được tính như thế nào? “EBITDA” trong context của tổ chức này được tính ra sao?
- Link glossary terms với actual columns trong tables – khi user xem column “mrr”, họ thấy ngay business definition
- Phân cấp glossary theo domain (Finance, Product, Marketing…)
- Approval workflow để đảm bảo definitions được validate bởi domain experts
Ownership trong OpenMetadata:
- Assign owners (cả individual và team) cho mỗi data asset
- Phân biệt Technical Owner (data engineer maintain the pipeline) và Business Owner (domain expert chịu trách nhiệm về business definitions)
- Tự động route questions và issues đến đúng người
- Track orphaned assets (assets không có owner – data governance risk lớn)
4. Policy & Security (Chính sách và bảo mật)
OpenMetadata hỗ trợ governance policies:
- Data classification – tag data assets theo sensitivity level (Public, Internal, Confidential, PII, PHI)
- Access policies – define ai được xem metadata của assets nào
- Role-based access control (RBAC) – phân quyền theo roles
- Data masking rules – hide sensitive data trong previews và sample data
- Audit logs – track ai xem, sửa hoặc xóa metadata
- Compliance support – hỗ trợ GDPR, CCPA, HIPAA compliance workflows
LUỒNG TÍCH HỢP CỐT LÕI: Schema & Metadata Deployment
Đây là luồng quan trọng nhất trong kiến trúc – cách Hackolade và OpenMetadata “nói chuyện” với nhau:
Luồng Xuôi: Từ Design Đến Governance
Bước 1 – Design trong Hackolade: Data Architect tạo hoặc cập nhật schema, thêm business descriptions cho mỗi table và column, gắn tags và định nghĩa ownership.
Bước 2 – Review & Approval trong Git: Schema change được committed vào Git, tạo Pull Request. Data Engineers và Business Owners review và approve.
Bước 3 – Schema Deployment vào Data Warehouse: Sau khi merge, CI/CD pipeline tự động deploy schema changes vào Snowflake/BigQuery/AWS. Hackolade generate và execute DDL scripts.
Bước 4 – Metadata Publishing sang OpenMetadata: Song song với schema deployment, Hackolade publish metadata (descriptions, tags, ownership, business context) sang OpenMetadata qua API. Metadata này “enriches” technical metadata mà OpenMetadata đã crawl từ Data Warehouse.
Luồng Ngược: Metadata & Lineage Sync
Metadata Sync từ Data Warehouse lên OpenMetadata: OpenMetadata liên tục crawl metadata trực tiếp từ Snowflake, BigQuery, AWS – discovering new tables, tracking schema changes, capturing statistics. Đây là cơ chế giúp OpenMetadata luôn phản ánh trạng thái thực tế của data warehouse, không phải chỉ những gì được document.
Lineage Sync: OpenMetadata auto-discover lineage từ dbt project files, SQL query history trong Snowflake/BigQuery, Airflow DAG definitions và Spark job logs. Column-level lineage được tự động traced mà không cần manual input.
Sự kết hợp của hai luồng này tạo ra một bi-directional metadata layer – metadata không chỉ được “push” từ design xuống mà còn được “pulled” từ thực tế production lên.
TẠI SAO TÍCH HỢP HACKOLADE + OPENMETADATA LÀ QUAN TRỌNG?
Giải Quyết “Schema Drift”
Schema drift xảy ra khi schema trong production khác với design document. Với tích hợp này, Hackolade là source of truth cho design, còn OpenMetadata track thực tế. Khi có drift, cả hai hệ thống đều có thể alert và trigger review process.
Tạo Ra “Design-Time Governance”
Thông thường, data governance được áp dụng sau khi dữ liệu đã vào production (reactive). Với kiến trúc này, governance bắt đầu ngay từ design phase (proactive):
- Business descriptions được viết khi thiết kế schema, không phải sau khi deploy
- Ownership được assign trong design tool, không phải sau khi có data quality incident
- Tags và sensitivity classification được áp dụng trước khi data tồn tại
Một Source of Truth Cho Metadata
Thay vì có metadata rải rác ở Confluence pages, email threads, Excel files và database comments, kiến trúc này tạo ra một source of truth duy nhất:
- Hackolade = source of truth cho schema design và intended metadata
- OpenMetadata = source of truth cho discovered metadata, lineage và quality
SO SÁNH VỚI CÁC GIẢI PHÁP THAY THẾ
| Khía cạnh | Hackolade + OpenMetadata | Traditional Approach |
|---|---|---|
| Schema Documentation | Auto-synced, always current | Manual, often outdated |
| Data Lineage | Automatic discovery + design-time | Manual mapping in spreadsheets |
| Business Glossary | Linked to actual columns | Separate documentation |
| Data Discovery | Unified search across all assets | Ask team members |
| Schema Changes | Git-controlled, auditable | Email/chat, hard to track |
| Governance | Embedded in workflow | Post-hoc, reactive |
| Cost | Open-source (OpenMetadata) | Enterprise license costs |
AI NÊN SỬ DỤNG KIẾN TRÚC NÀY?
Kiến trúc Hackolade + OpenMetadata phù hợp với:
Data teams từ 5 người trở lên nơi sự phối hợp giữa architects, engineers và analysts trở nên phức tạp.
Tổ chức đang scale data infrastructure – từ một data warehouse đơn giản lên multi-source, multi-team data platform.
Tổ chức có yêu cầu compliance nghiêm ngặt (tài chính, y tế, bảo hiểm) cần audit trail rõ ràng cho data lineage và schema changes.
Teams đang implement Data Mesh – OpenMetadata hỗ trợ domain-based ownership và data products, Hackolade hỗ trợ thiết kế schema theo domain.
Tổ chức muốn giảm “data tribal knowledge” – khi chỉ 2-3 người biết dữ liệu ở đâu và có nghĩa gì, đây là rủi ro lớn khi họ rời tổ chức.
BẮT ĐẦU NHƯ THẾ NÀO?
Nếu bạn muốn implement kiến trúc này, đây là lộ trình thực tế:
Phase 1 – Foundation (1–2 tháng): Deploy OpenMetadata (self-hosted hoặc cloud), kết nối với data warehouse hiện tại để auto-discover metadata. Assign owners cho top 20 most-used tables.
Phase 2 – Governance Setup (2–3 tháng): Xây dựng Business Glossary cho các core business terms. Implement data quality tests cho critical tables. Enable lineage tracking cho dbt models và Airflow DAGs.
Phase 3 – Design Integration (3–4 tháng): Implement Hackolade cho new schema designs. Thiết lập Git workflow với PR reviews. Bắt đầu publish metadata từ Hackolade sang OpenMetadata.
Phase 4 – Full Integration (Ongoing): Tự động hóa schema deployment qua CI/CD. Enable column-level lineage. Expand glossary coverage. Train toàn bộ team về data discovery workflow.
Kết Luận
Kiến trúc tích hợp Hackolade + OpenMetadata đại diện cho một cách tiếp cận hiện đại, thực tiễn cho vấn đề cũ: làm thế nào để duy trì data governance thực sự trong khi data stack ngày càng phức tạp và số lượng data assets ngày càng tăng?
Câu trả lời là tích hợp governance vào design workflow, không phải thêm governance như một tầng riêng sau khi tất cả đã xong. Khi schema design tool (Hackolade) nói chuyện với data catalog (OpenMetadata), và khi data catalog liên tục sync với data warehouse thực tế, bạn có một hệ thống tự duy trì sự đồng bộ giữa thiết kế và thực tế, giữa kỹ thuật và kinh doanh.
Tổ chức của bạn đang dùng công cụ nào cho data modeling và data catalog? Bạn đã gặp vấn đề “schema drift” hoặc “metadata out of sync” chưa? Hãy chia sẻ kinh nghiệm trong phần bình luận!
